Overview
Predibase provides the interfaces and infrastructure to fine-tune and serve open-source Large Language Models (LLMs). In this section, we will cover how to easily get started with inference.
Definitions
- Model: A pretrained base model that you can deploy and query (e.g. llama-2-7b, mistral-7b)
- Adapter: a set of (LoRA) weights produced from the fine-tuning process to specialize a base model
Inference Options
There are two main ways to run inference on Predibase:
- Private Serverless Deployments: Predibase can host nearly any open-source LLM on your behalf using dedicated hardware ranging from A10Gs to a multiple H100s.
- Shared Endpoints: Predibase hosts the most popular base models that can be queried or fine-tuned (via Adapters). These endpoints are intended for experimentation and fast iteration and are subject to rate limits
See our pricing page for more details here.
LoRAX (LoRA eXchange): Serving fine-tuned models at scale
LoRAX is an open-source framework released by the team at Predibase that allows users to serve up to hundreds of fine-tuned models (i.e. adapters) on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency. You can choose to use LoRAX with our shared endpoints or private serverless deployments.
Private Serverless Features
Autoscaling
Predibase offers seamless autoscaling, allowing you to scale down to 0 replicas when the deployment is not in use and automatically scaling up to multiple replicas to meet your demand. Min and max replicas can be configured in the UI or SDK.
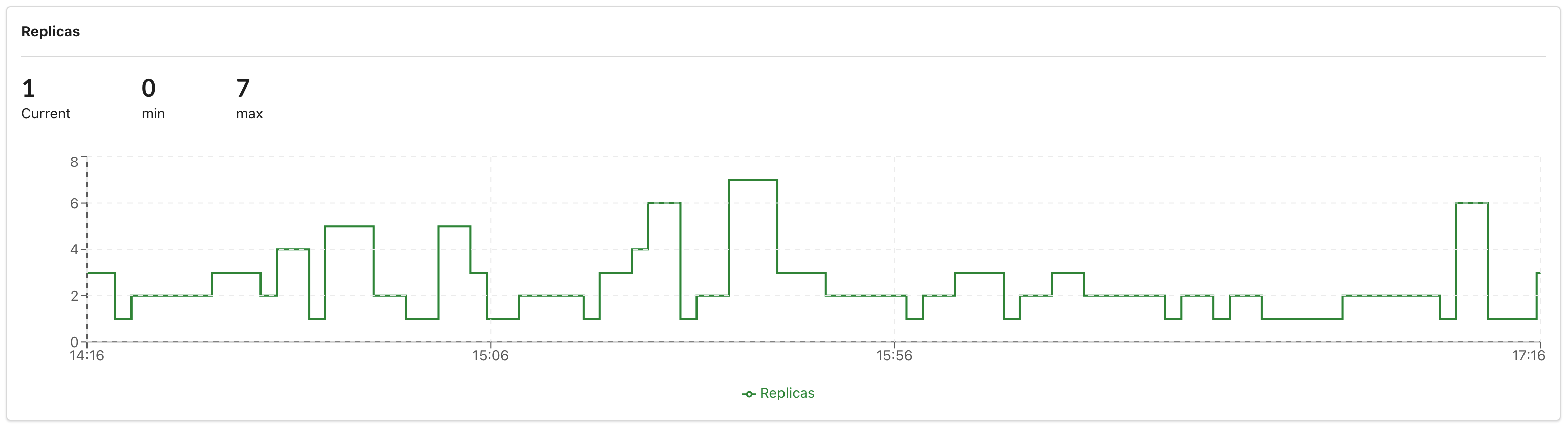
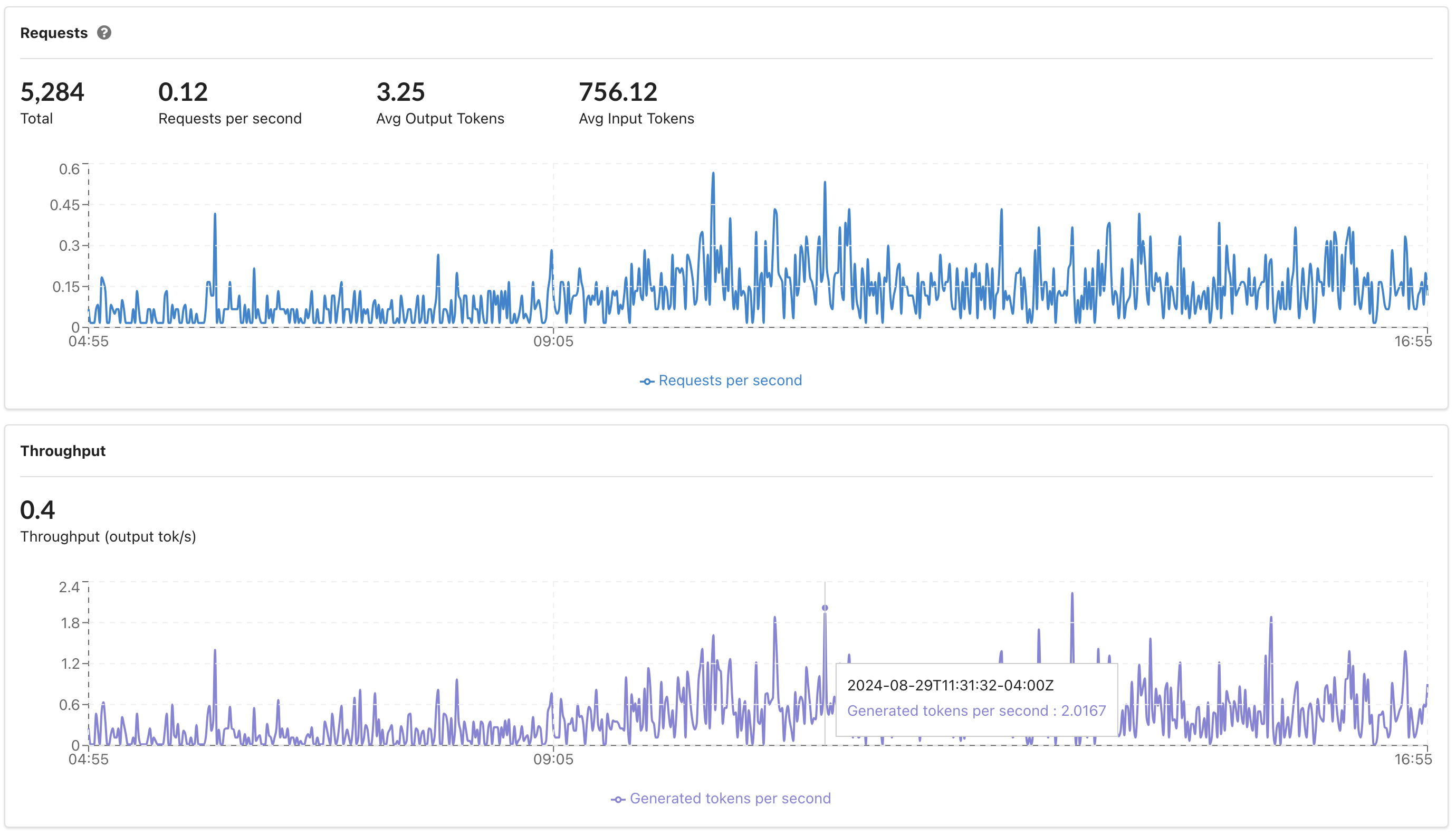
Monitoring
After creating your deployment, you can view live updating charts in the UI by going to your private deployment's page > Health tab. View metrics and graphs, such as:
- Requests per second
- Throughput (generated tokens per second)
- LoRAX inference time
- Queue duration
- Replicas
- GPU utilization
Deployment Statuses
Private Serverless Deployments that are created in Predibase can be in any of the following states:
- Pending — Deployment record has been created, but deployment has not been fully created yet
- Initializing — The first replica is in the process of being spun up
- Ready — At least 1 replica is up and live
- Standby — 0 replicas are up but deployment is ready to scale up on request
- Stopped — 0 replicas are up and deployment will not scale up until moved to Standby
- Errored — 0 replicas are up and last Initializing state led to an error
- Updating — at least 1 replica is up and either:
- needs to be re-initialized following a config change OR
- the LLM is in the process of being re-initialized
- Deleted — The deployment has been deleted
OpenAI-compatible API
For users migrating from OpenAI, Predibase supports OpenAI compatible endpoints that serve as a drop-in replacement for the OpenAI SDK. Learn more here.